
The A100 brings the five important innovations from NIVIDA, that accelerate your GPU computing loads, while also bringing revolutionary new agility in elastic GPU compute.
NVIDIA Ampere architecture is the latest innovation in GPU architecture, and includes genuine improvements in performance, connectivity and flexibility.
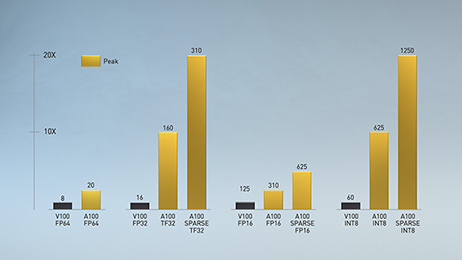 Third Generation Tensor Cores. First introduced in the Volta architecture, NVIDIA Tensor cores delivered dramatic increases in processing speed to AI, reducing training time from weeks to hours and accelerating inference. The third generation Tensor Cores in the Ampere architecture of the A100 builds on these innovations and brings new precision – Tensor Float (TF32) and Floating Point 64 (FP64) to accelerate and simplify AI adoption. TF32 can deliver up to 20x acceleration in AI processing without any code changes.
Third Generation Tensor Cores. First introduced in the Volta architecture, NVIDIA Tensor cores delivered dramatic increases in processing speed to AI, reducing training time from weeks to hours and accelerating inference. The third generation Tensor Cores in the Ampere architecture of the A100 builds on these innovations and brings new precision – Tensor Float (TF32) and Floating Point 64 (FP64) to accelerate and simplify AI adoption. TF32 can deliver up to 20x acceleration in AI processing without any code changes.
Multi-Instance GPU (MIG). Every AI and HPC application can benefit from Ampere acceleration, but not every application needs 100% if the horsepower available in the A100. With MIG, NVIDIA delivers elastic functionality, allowing each A100 to be partitioned into as many as seven GPU instances which are fully isolated and secured at the hardware level with their own high bandwidth memory, cache and compute cores. With MIG, you can now optimise your GPU resources and provide any combination of GPUs from 1 to 7 with guaranteed quality of service.
Third Generation NVLink. Connectivity between GPU’s now connected doubled 600 GB/s.
Structural Sparsity. With modern AI networks getting larger and larger, parameters can blow out to millions, or even billions in a data set. Not all of these parameters are needed for accurate predictions and inference, and some can be converted to zeros to make the models “sparse” without compromising accuracy. The Tensor Cores in the A100 can provide up to 2x higher performance for sparse models, which can hugely benefit both AI inference and also model training.
Smarter and faster memory. The A100 delivers massive amounts of compute power, and to keep this fully utilised you need equally fast memory. The A100 has 1.6 TB/s memory bandwidth, a 67% increase over previous generation V100 GPUs. Additionally, the A100 has significantly more on-chip memory including 40MB of level 2 cache – 7x larger than previous generation GPUs.
PCIe Generation 4. The A100 utilises PCIe Gen4 technology, and requires a server with PCIe Gen4 in order to make the most of the transfer speeds and capabilities of the A100. XENON has recently announced two new NITRO servers with PCIe Gen4 for the new A100’s – the XENON NITRO GX49A and the XENON NITRO G29A.
Shipping Now!
The A100 PCIe card started shipping in early September 2020, and is available now! XENON can build a custom spec server that will make the most of the A100 capabilities. We have two new models available now which feature multi-core CPU, ultra-fast memory and PCIe4 – the NITRO G29A and the NITRO GX49A. Contact XENON today and prepare to launch your workloads on the A100!
Read the full specs and learn more about the A100 PCIe GPU Card.
Talk to a Solutions Architect

