
 A New Approach to Processing Machine Learning and AI
A New Approach to Processing Machine Learning and AI
Graphcore’s Intelligence Processing Unit (IPU) is a new processing architecture specifically designed for machine learning and artificial intelligence (ML/AI).

IPU-M2000
CPU processing has proven too linear and slow for ML/AI. GPUs are the architecture of choice for ML/AI and can exploit massive compute parallelism. However, in order to complete ML/AI workloads GPUs require an abundance of processors and are often in-processor memory constrained. While better than CPUs, current generation GPUs are hitting a ceiling as they were designed for smaller graphics application and data sets, not for the large data sets and non-linear I/O patterns that come with modern machine learning models.
Established in 2016 in the UK, the Graphcore team began designing a new processing unit that can handle the large data sets used in ML/AI, and can processes problems in parallel easily within a unified architecture. Graphcore started shipping their first IPU units in PCIe form factors in 2018. Graphcore then brought server based models to market in 2019. In that short time, Graphcore has made a huge impact in the machine learning space, with significant installations across scientific research, weather modelling and financial market trading. Graphcore’s approach has delivered impressive results in these areas where large data set models are the norm.
Real World Results: Predicting Stock Price Movements
A group of researchers at Oxford University demonstrated the power of the new IPUs when they created an AI model that can predict stock price movements with 80% accuracy over a short time-frame. This modelling works on the Graphcore system because it relies on large data sets and the parallel processing power of the IPU.
Hear the story from the researchers in the video below (approx 5min).
Real World Results: University Research Adopting IPUs
Universities have adopted Graphcore’s IPUs to accelerate a range of research activities – from CERN and particle physics to Astronomy and Medical Research.
Recently, the researchers from the University of Massachusetts, Facebook and Graphcore published a paper showing how the Graphcore IPU stack accelerated their COVID-19 modelling. Using Approximate Bayesian Computation their models were accelerated by 30x on the IPU when compared to CPU s and 7.5x when compared to GPUs. The increased speed allows researchers to crunch more data, providing more predictions on the spread and recovery rates of populations fighting COVID-19. The Graphcore IPU is able to make these impressive gains through the architecture of their chips – with more onboard memory for these larger datasets, less I/O fetches, and faster parallel processing.
See the presentation of the paper in the video below (approx 11 min).
What Makes the IPU and IPU PODs?
Graphcore’s IPU is allowing scientist to undertake entirely new types of work not possible with other processors. The IPU is designed specifically for machine learning and AI workloads – with massive in accelerator memory and the ability to crunch larger models faster.
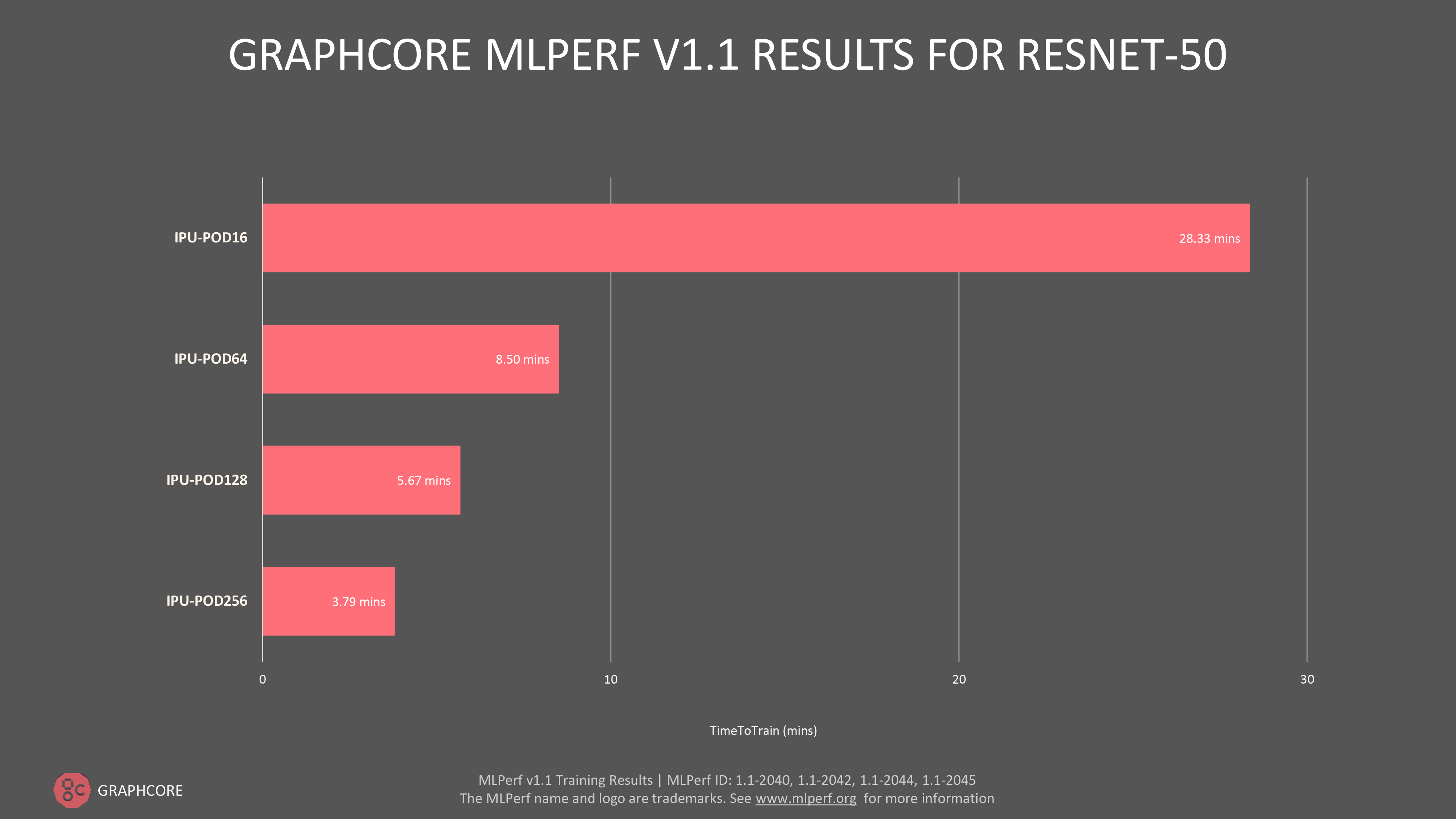
The current generation IPU POD16 has 16 IPUs with 14.4GB in-processor memory and 1024GB streaming memory and performs 4 petaFLOPS FP16.16. The IPU POD 16 is the foundational POD structure, and reference architectures run to POD64, POD128 and POD256 (which hits 64 petaFLOPS FP16.16).
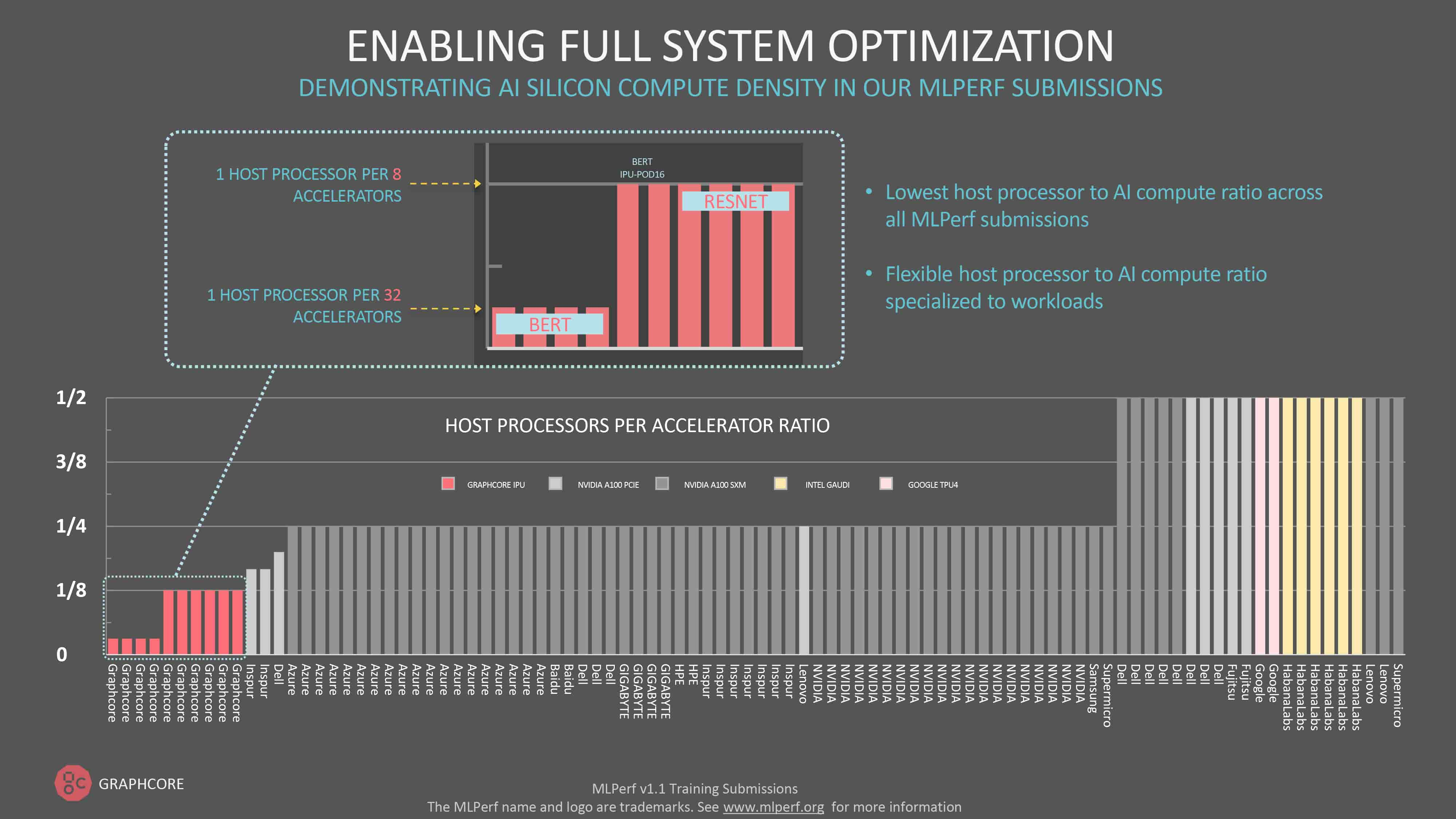
An interesting feature is how Graphcore approaches scalability across the POD family. Using a modular approach, they have separated out the IPU from the CPUs required to coordinate processing (compared to other GPU based systems which include a fixed ratio of processors per GPUs). The Graphcore approach allows ML architecture to be built up with the right number of IPUs for the tasks at hand. This results in an up to 1.6x advantage of processing power per $$ over rival systems (see image below from the recent MLPerf submissions).
Graphcore continues to expand and enhance their range of software tools, as the ML/AI stack is about more than just processing grunt. Graphcore IPUs run the Poplar Graph framework software which makes the most of the IPU architecture. The Poplar SDK is fully integrated with standard machine learning frameworks so existing models can be easily ported across to Poplar (and Graphcore IPUs). Integrations include TensorFlow, PyTorch, PopART ML frameworks. The Poplar framework also enables direct IPU programming in Python and C++, and the Poplar Graph libraries are open source. The Graph Complier simplifies programming by handling scheduling and memory control, which optimises programs easily to maximise performance on the IPU systems. Scalability is handled by high bandwidth IPU-Link communications and the tools automatically create multi-IPU parallelism.
Graphcore recently released updates to the Poplar SDK with their submission to the latest MLPerf performance tests. Their results show impressive gains with further optimisation of the Polar SDK stack. In addition providing ease of use updates, the new SDK is resulting in faster processing, training and inference. The base IPU POD16 is now faster than baseline GPU systems which are twice the price. Graphcore also showed the lowest ratio of host server CPU to accelerators across the range of submissions, providing a lower TCO in capex server purchasing and opex in power and cooling. See the full results on the Graphcore website here.
Shipping Now!
XENON is delivering solutions with the full range of Graphcore’s systems in Australia and New Zealand, including the latest third generation Bow systems released in March 2022:
- Bow Pod16 – 4 interconnected IPU-M2000’s and 1 host server with 16 IPUs, running up to 5.6 petaFLOPS at FP16.
- Bow systems scale from Pod16 all the way to Pod1024, and deliver performance that scales linearly.
Review these units and more in the Graphcore section of our products showcase here.
XENON has already delivered the first Graphcore system to a well known Australian University, and we’ll be showcasing their work with this new system in the new year.
If you would like to learn more about Graphcore IPUs and how they can benefit your artificial intelligence workloads, please contact XENON today!
Talk to a Solutions Architect

